옴니어스에서는 2020년부터 모든 서비스를 Kubernetes 기반으로 운영하고 있습니다. 이를 통해 다년간 서비스 이용 경험을 토대로 표준화된 인터페이스와 오토스케일링 등 안정적인 서비스 운영에 필요한 다양한 기능을 갖추어 적은 인력으로도 서비스 운영에 필요한 리소스를 크게 줄일 수 있었습니다. 이는 개발자들이 운영 요소보다 서비스 개발과 개선에 더 집중할 수 있도록 도움을 주는 반면, 기능이 자주 업데이트되는 만큼 클러스터를 운영하는 관점에서는 살짝 부담이 되기도 합니다.
현재 옴니어스는 On-premise를 비롯, AWS, GCP 등 여러 클라우드를 모두 이용하고 있습니다. 그 중 AWS의 EKS의 경우, kubernetes 버전이 정식 Release 이후 거의 1년 남짓 동안만 Support를 해주는데, 이는 정식 Support를 안정적으로 받기 위해서는 해당 기간 내에 Cluster의 Kubernetes 버전을 최신으로 업데이트해야 한다는 의미입니다.
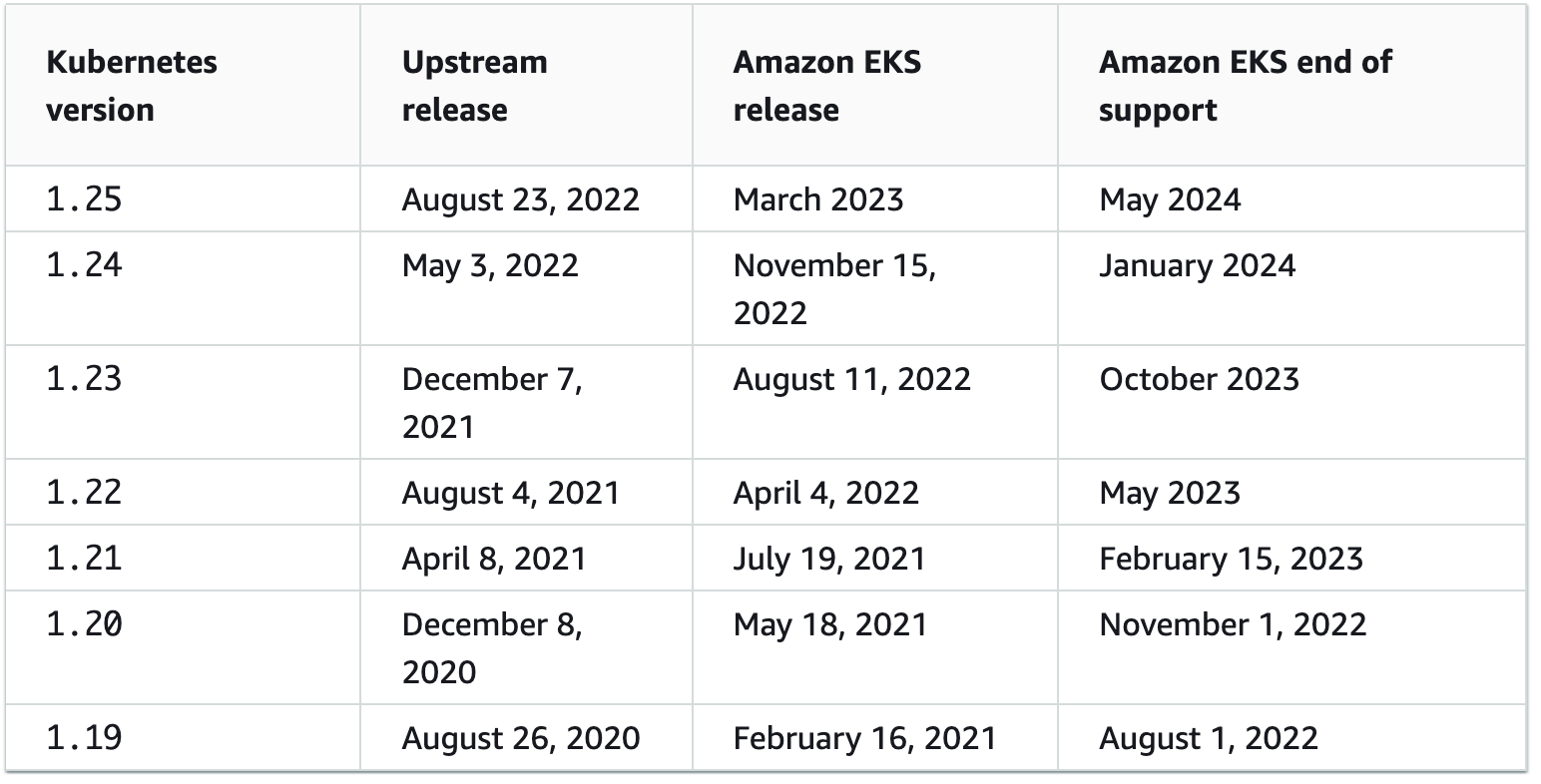
2022년 초에 이미 1.21 버전으로 한차례 업데이트를 한 지도 벌써 1년이 지나가고 있었고, 1.21 버전의 서비스 종료일이 2023년 2월로 다가오고 있었기에 2022년 12월 부터 업그레이드 작업에 대한 필요성을 인지하고 준비를 시작하였습니다.
서비스 유형 별 방안
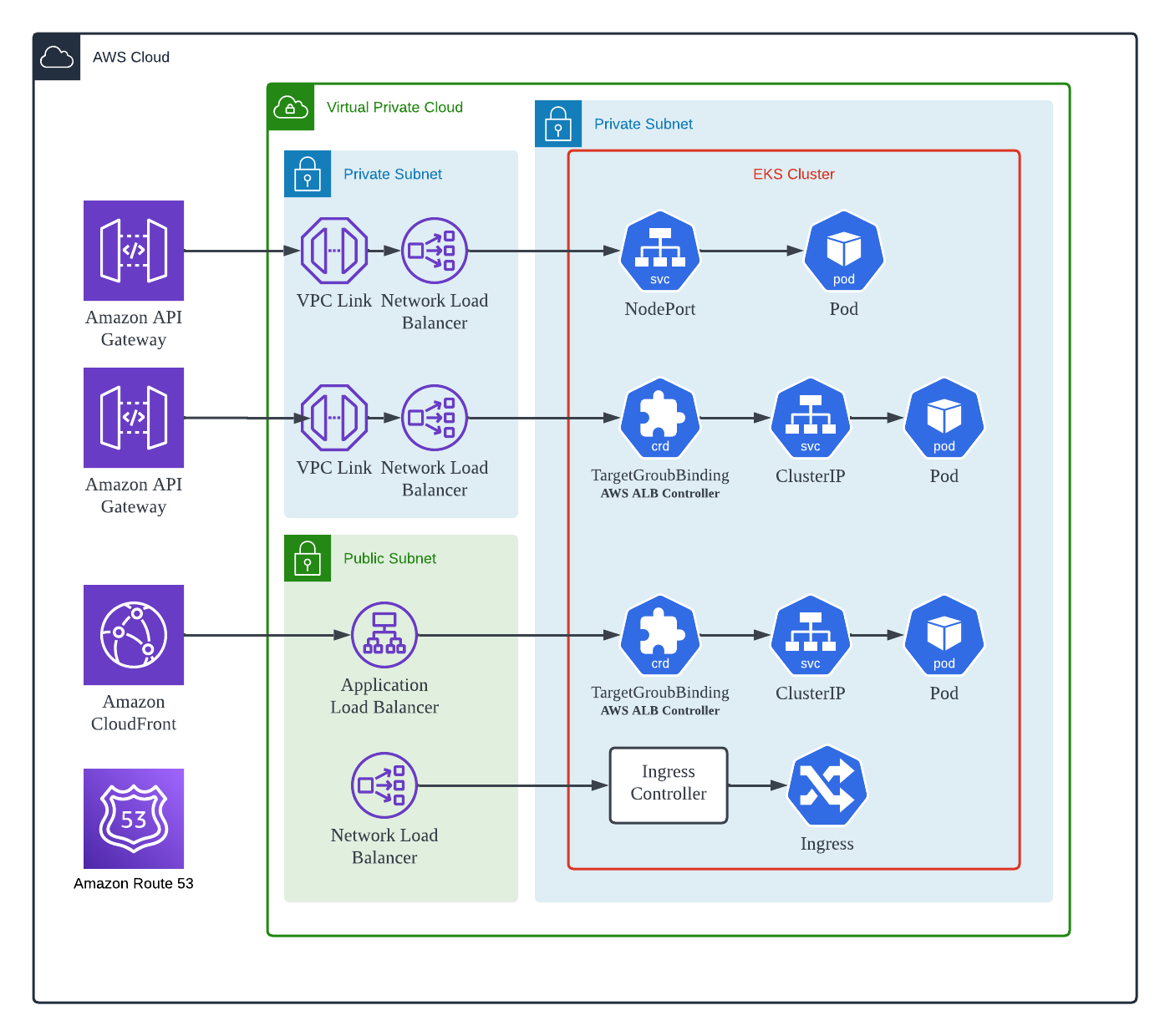
2022년 초와는 달리, 서비스 확장과 사용 고객 증가로 인해 업그레이드 작업에 앞서 운영 현황을 더욱 면밀하게 조사해야 했습니다. 따라서 12월 한 달 동안 시간을 내어 조사 및 정리를 진행한 결과, Cluster 업그레이드 진행 시 서비스에 바로 영향이 갈 수 있는 구성은 크게 네 가지 유형으로 분류할 수 있었습니다 ([그림1] 참조).
Cluster를 직접 업그레이드하면 서비스가 일시 중단될 위험이 있기 때문에, 1.24 버전의 새로운 EKS Cluster를 생성하고 Workload를 무중단으로 하나씩 이전하는 방식으로 업그레이드 작업을 진행하기로 결정했습니다. Migration 기간 중 서비스 운영 비용이 증가하는 점을 감안하더라도, 이 방식은 업그레이드 작업 중 문제가 발생할 경우 바로 Rollback이 가능한 이점을 가지고 있습니다.
따라서, 2022년 12월부터 2023년 1월까지는 운영 환경과 유사한 개발용 Cluster 환경에서 네 가지 서비스 유형별로 Migration 방안을 마련하고 실험을 진행했습니다. 결과적으로 아래와 같이 진행하면 무중단으로 진행이 가능함을 확인했습니다.
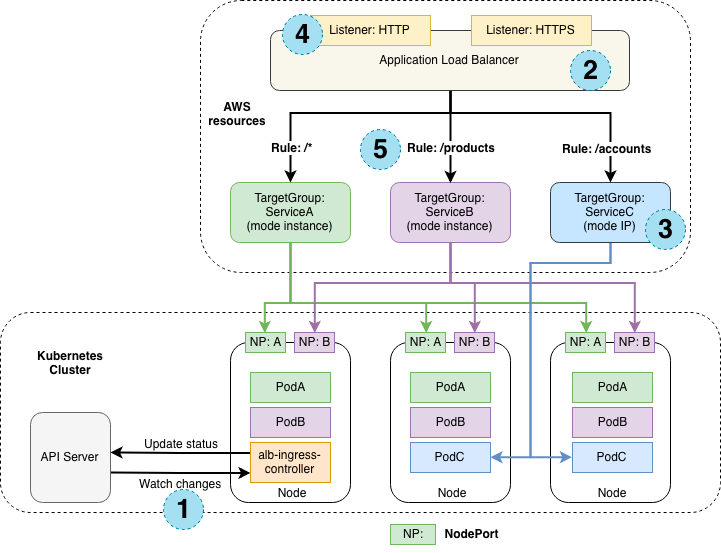
유형1. NodePort를 통해 Load Balancer와 연결된 Workload
[그림1] 에서 맨 위의 항목으로 정리된 유형으로, 가장 오래 전 부터 서비스에 적용된 연결 방식입니다. Cluster 밖에서 Terraform 이나 Spotist 와 같은 3rd Party Solution을 이용해 Load Balancer의 Target Group에 Cluster에 등록된 Node들을 직접 등록하거나 등록 해제 합니다. 외부 트레픽을 제어하는 요소가 Cluster와 무관하므로 서로 다른 EKS Cluster에서 동작하는 Workload들도 하나의 Target Group에 연동할 수 있습니다.
따라서, [그림2]와 같이 Blue/Green 방식을 이용하여 무중단으로 자연스럽게 기존 버전 Cluster에서 새 버전 Cluster로 Traffic을 전환하는 방식으로 Migration을 진행했습니다.
유형2. ALB Controller를 통해 Pod IP Type으로 Network Load Balancer와 연결된 Workload
2022년 중반 부터 적용하던 방식으로, AWS Load Balancer Controller 에서 정의된 TargetGroupBinding 이라는 Custom Resource로 Workload Pod을 Target Group에 바로 연동할 수 있습니다. 이 방식은 [그림3]에서 (3)으로 표시되는 방식으로, AWS EKS에 속한 Node의 EC2 Instance에 직접 부여된 Pod IP를 Load Balancer에서 사용하기 때문에, 추가적인 Network Layer를 거치지 않아 다른 방식에 비해 AWS 서비스에서 효율적입니다.
이 방식은 서비스 운영 관점에서 매우 매력적인 구성이어서, 해당 방식을 적용하고 운영할 때는 문제가 없다고 생각했지만, 이번 Cluster Migration을 진행하면서 문제에 직면했습니다.
처음에는 유형1([그림2] 참조)과 같이 하나의 Target Group에 서로 다른 Cluster에 속한 Workload의 Pod IP를 등록하여 Migration을 진행하고자 했습니다. 그러나 Target Group에 Pod IP를 각 Cluster에서 동작 중인 ALB Controller가 수행하면서 문제가 발생했습니다. 동일한 Target Group을 서로 다른 Cluster에서 바라보게 되면, 각 Cluster의 ALB Controller는 각자의 Cluster에서 유효한 Pod IP를 제외한 모든 다른 요소를 삭제하게 되므로, 이로 인해 서비스 중단이 발생합니다.
이 문제에 대한 공식적인 대응 방안이 있는지 확인하기 위해 Open Source Project인 ALB Controller의 Github issue를 찾아보았는데, 아래와 같이 현재는 해당 방법이 지원되지 않으며, 차기 버전에서 고려 중이라고 합니다.
 kubernetes-sigs
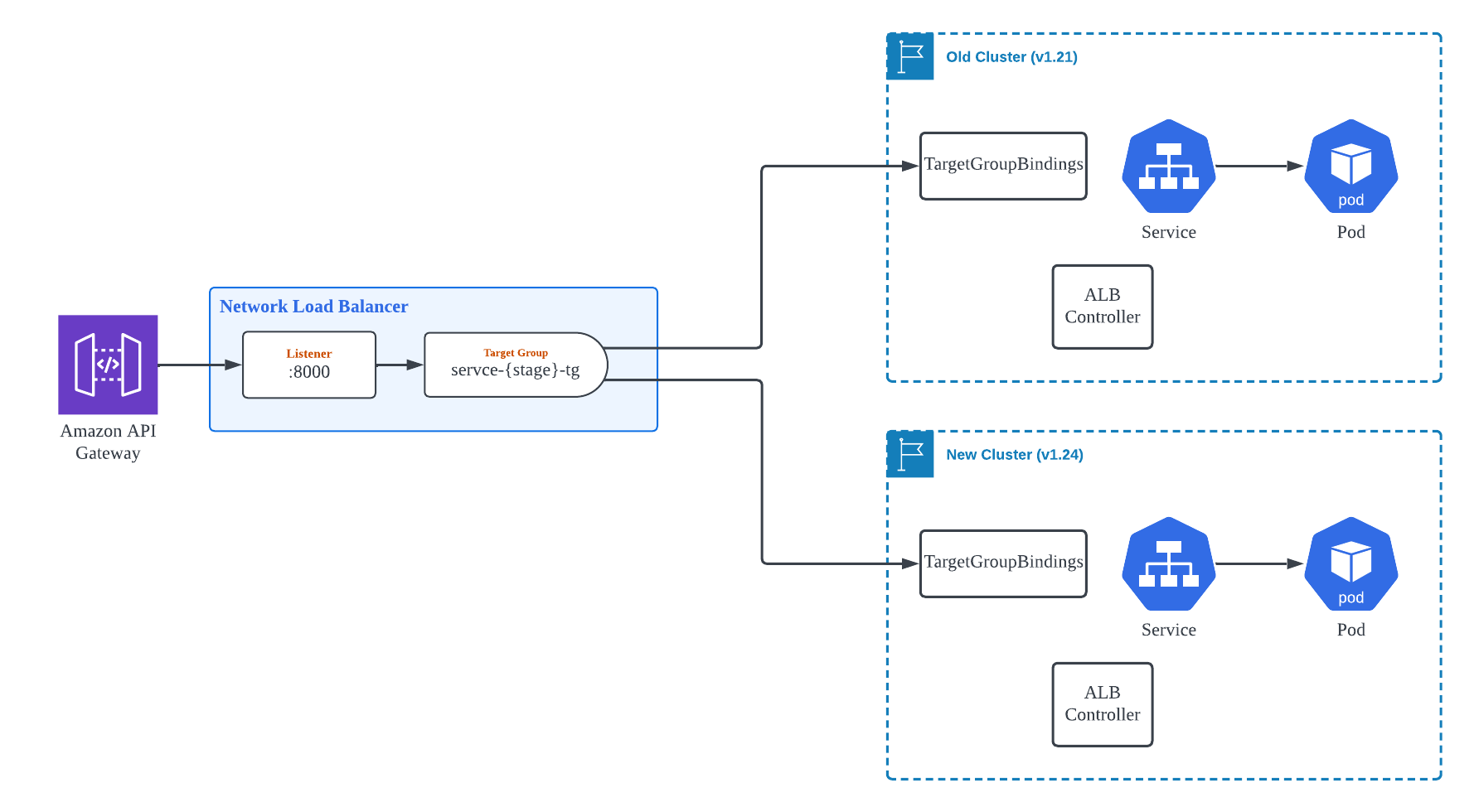
kubernetes-sigs이에 어떻게 무중단으로 진행을 할까 고민을 하다가 결국, Target Group을 독립적으로 만들고 그 이후의 Layer에서 Blue/Green 방식의 배포를 하는 방안을 마련하였습니다.
[그림4]와 같이 두 개의 Target Group을 구성하고, 각 Target Group은 개별적으로 하나의 EKS Cluster와 연동합니다. NLB의 경우 Listener 당 하나의 Target Group만 연결 가능하므로, 새로운 Port 번호로 Listener를 생성합니다. 두 개의 Target Group과 Listener가 Healthy 상태가 된 이후, API Gateway의 Resource 별 Integration 설정에서 바라보는 Backend의 Port 번호를 교체하여 Traffic이 기존 Cluster에서 신규 Cluster로 자연스럽게 전환되도록 합니다.
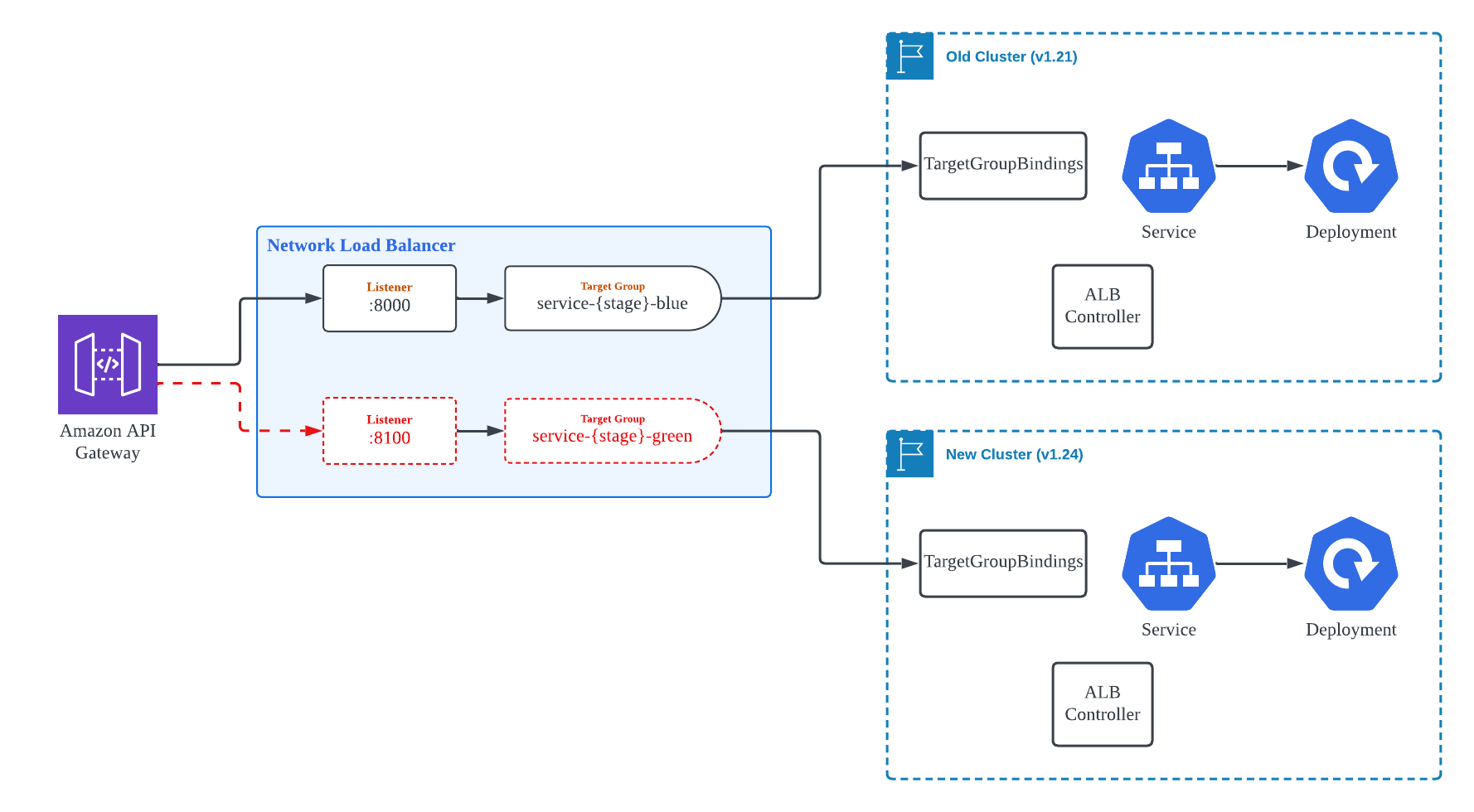
이 방법은 작업을 진행하는 동안 API Gateway, NLB Listener, NLB Target Group, 그리고 이와 연계된 Security Group 등 수정해야하는 AWS Resource가 많기 때문에, Terraform의 for_each, count, dynamic block 등의 제어 구문을 이용하여 최대한 사람이 제어해야 할 부분을 간소화하여 module화 하고, variable을 통해 제어할 수 있도록 하였습니다.
그 결과 실제로 운영 환경에서 해당 유형의 Workload를 Migration 하는 작업을 서비스 중단이나 장애 없이 개발자 1명이 1~2시간 이내로 마칠 수 있었습니다.
유형3. ALB Controller를 통해 Pod IP Type으로 Application Load Balancer와 연결된 Workload
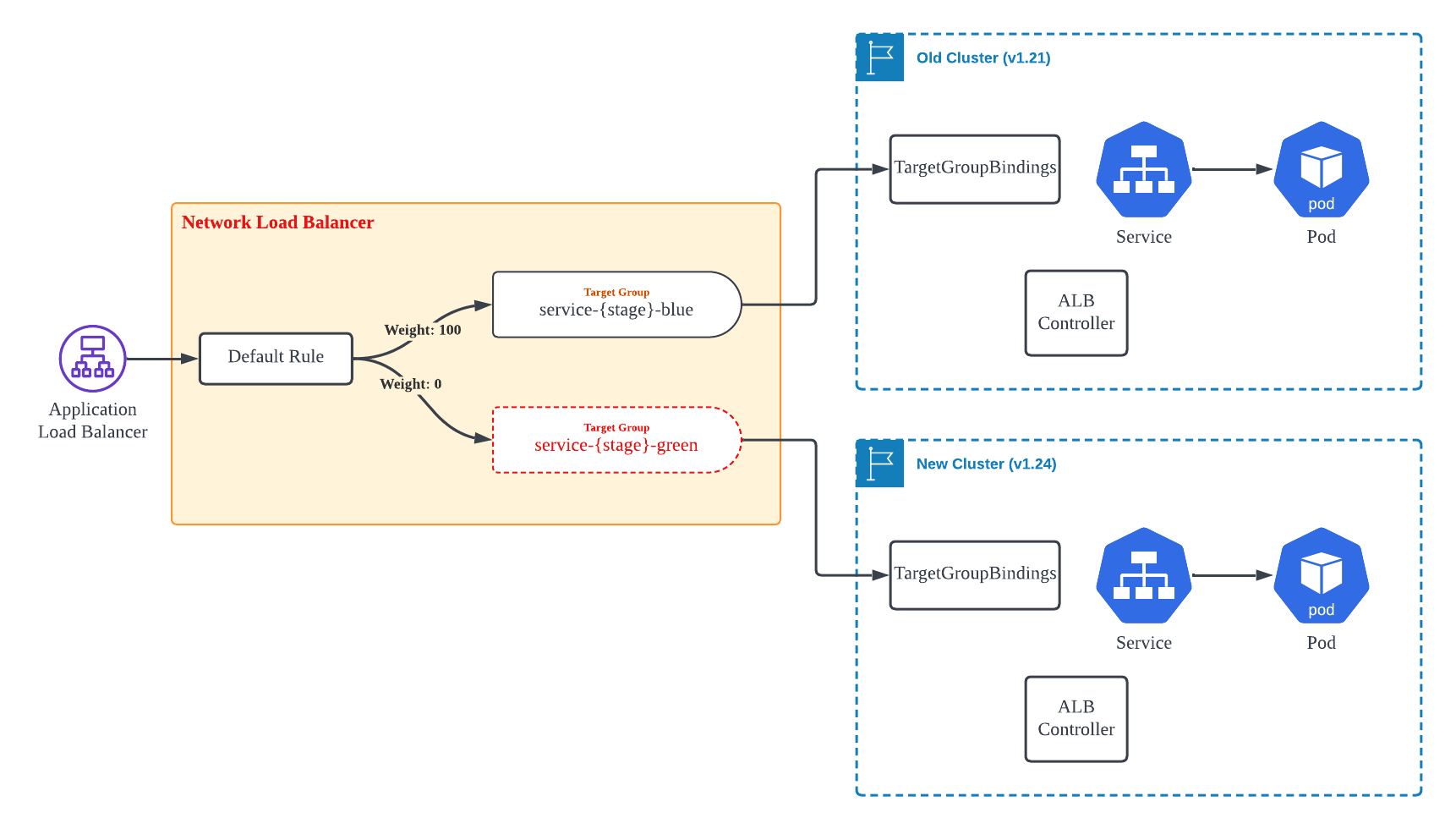
Application Load Balancer의 경우 Network Load Balancer보다는 작업이 더 수월했습니다. Target Group은 여전히 두 개를 만들어야 하지만, Routing Rule 설정을 통해 Target Group 별 가중치를 조정할 수 있습니다. 이는 2019년 후반에 출시된 기능 으로 이번 Migration 방안을 조사하면서 처음 알게되어 유용하게 활용했습니다.
[그림5]와 같이 처음에는 신규 Cluster와 연계된 Target Group을 Weight 0으로 등록하고, 신규 Cluster의 Workload가 준비되면 Weight를 변경하여 Traffic을 신규 Cluster로 전환했습니다. 이렇게 함으로써 Migration을 무중단으로 자연스럽게 진행할 수 있었습니다.
유형4. Ingress Controller로 연결된 Workload
[그림1]에 제시된 방법은 보통 내부 네트워크에서만 사용하는 서비스에 활용을 하였는데 무중단 운영이 필수적인 Workload가 없기 때문에, Migration 작업에 큰 부담이 없었습니다. 그러나 만약 무중단으로 Migration을 수행해야 한다면, Route53에 등록된 DNS Record를 활용하여 Traffice을 일부 제어할 수 있을 것으로 예상됩니다.
후기
실제로 운영중인 서비스에 영향을 줄 수 있기에 긴장을 하며 해야 하는 큰 작업이었습니다. 그래서 2022년 12월 부터 2023년 1월 까지 방안을 마련하고 테스트를 하는데에 거의 2달의 기간이 소요되었고, 각 서비스를 개발한 모든 개발자들도 해당 작업에 같이 참여하였습니다. 결과적으로 꼼꼼히 준비를 진행한 만큼 실제 운영환경 Cluster에서 Migration을 진행하는 데에는 약 1주일 정도 밖에 소요되지 않았으며 해당 기간 동안 실무 개발자들이 각 서비스 별로 하루 평균 1~2시간 정도만 짬을 내여 작업을 완료했습니다.
Kubernetes 버전 업데이트에 맞추어 내년 이맘때에도 비슷한 작업을 또 해야한다는 점이 부담이 되기는 하지만, 적극적으로 각자 개발을 진행한 서비스에 대한 책임감을 갖고 협조를 해주는 팀원 분들이 있기에 앞으로도 큰 문제는 없을 것 같습니다.





