
이번 포스팅에서는 쿠버네티스의 hpa의 기능을 확장하여 cpu나 memory 지표가 아닌 aws sqs 지표를 활용하여 autoscaling하기 방법에 대해서 소개하려고 합니다. autoscaling을 적용하기 위해 KEDA라는 오픈소스를 사용하였습니다. 쿠버네티스에서 오토스케일링에 대한 전반적인 내용부터 KEDA의 적용기까지의 내용을 다뤄보도록 하겠습니다.
들어가기 전에
본론에 들어가기 전에 쿠버네티스의 오토 스케일링 기능에 대해 간략하게 알아보겠습니다.
쿠버네티스에서 사용할 수 있는 오토스케일링 기법은 아래 3가지가 있습니다.
- HPA
- VPA
- CA
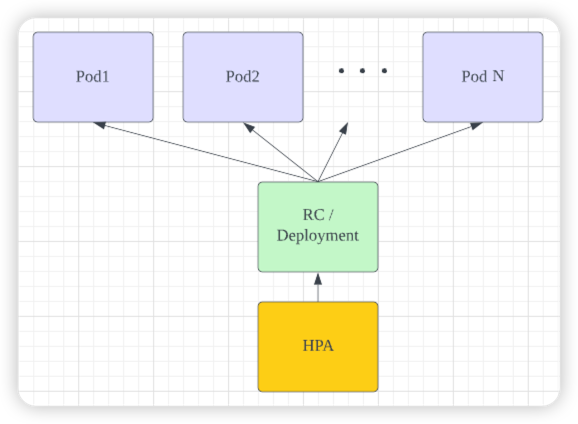
HPA (Horizontal Pod AutoScaling)
HPA는 대상 Pod의 리소스(cpu, memory)를 감시하여 리소스가 부족할 경우, replicas를 증가시켜 최종적으로 Pod가 증가되는 방식으로 동작합니다.
워커노드에 여유만 있다면 Pod이 대부분 빠르게 실행되기 때문에 stateless의 기동이 빠른 APP에 사용하는 것이 적절합니다.
VPA (Vertical Pod AutoScaling)
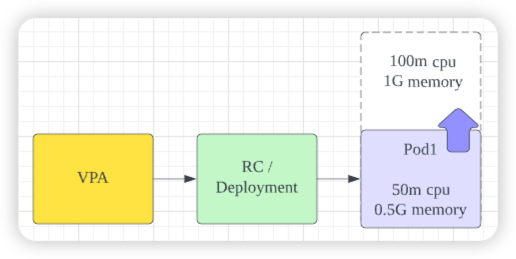
HPA와 동일하게 대상 Pod의 리소스를 감시하여 리소스가 부족할 경우, Pod의 재시작하여 Pod의 할당된 리소스를 증가시키는 방식입니다.
VPA는 Statefull한 APP에 사용하는 것이 적절하지만, 아직 Beta기능으로 기본 쿠버네티스에는 포함되어 있지 않아 별도로 설치가 필요합니다.
CA (Cluster AutoScaling, Cloud AutoScaling)
CA는 클러스토 혹은 클라우드 오토스케일링이라고 하며, aws, Azure, gcp와 같은 클라우드 인프라와 연동되어 워커노드의 자원이 모두 소모된 경우 Node의 수를 증가시킵니다.
본론
현재 옴니어스에서는 aws SQS 큐를 사용하여 데이터를 처리하고 있습니다.
쿠버네티스에 내장되어 있는 HPA기능으로는 CPU, Memory등과 같은 기본적인 지표로만 오토스케일링이 가능하다는 한계가 있기 때문에 SQS 지표 등으로 HPA를 확장한 KEDA를 적용하기로 하였습니다.
본론에서는 KEDA를 쿠버네티스 클러스터에 적용한 내용을 설명하겠습니다.
KEDA란?
KEDA는 쿠버네티스를 지원하는 오픈소스이며 CNCF incubating Project에 등록되어 있습니다. 라이선스는 Apache-2.0이므로 자유롭게 사용이 가능합니다.

KEDA를 사용하면 쿠버네티스의 기본 HPA의 지표를 넘어서서 좀더 많은 지표를 이용하여 오토스케일을 구현할 수 있습니다.
KEDA가 지원하는 Scalers
KEDA는 아래 그림과 같이 수많은 Scaler를 지원하고 있으며 계속 업데이트 되고 있습니다.

설치하기
설치는 helm 차트를 이용하여 쿠버네티스 클러스터에 간단하게 설치할 수 있다.
helm Repo 추가하기
helm repo add kedacore https://kedacore.github.io/charts
helm Repo 업데이트하기
helm repo update
KEDA 네임스페이스 생성하기
kubectl create namespace keda
KEDA 설치하기
helm install keda kedacore/keda --namespace keda
설치 방법은 helm 이 외에도 yaml파일로 직접 설치하거나 Operator Hub로도 설치가 가능합니다.
자세한 내용은 아래 Installation 문서를 참조해주세요.
AWS 권한 추가하기
KEDA를 설치하면 keda-operator라는 Deployment를 확인할 수 있는데요. 이 keda-operator가 메트릭을 수집하는 metric adaptor 역할을 합니다.
aws SQS의 지표에 맞춰서 오토스케일링을 하기위해서는 keda-operator가 aws SQS의 지표에 접근할 수 있는 권한을 추가해줘야 합니다.
aws permission policy
{
"Statement": [
{
"Action": [
"cloudwatch:GetMetricData"
],
"Effect": "Allow",
"Resource": "*"
}
],
"Version": "2012-10-17"
}
가장 간단한 방법으로는 AWS Credential을 이용하는 방법이 있지만, 옴니어스에서는 보안을 위해 꼭 필요한 권한만 부여하고 있어 IRSA 방법을 통해 role을 생성하고 kubernetes serviceAccount를 통해 권한을 부여하고 있습니다.
이에 관한 구체적인 방법은 아래 aws 문서에서 확인할 수 있습니다.

iam role 생성이 완료되었다면 해당 arn을 values.yaml파일에 적용하고 helm 재설치 or 업데이트를 진행하면 됩니다.
keda-operator의 적용되는 ServiceAccount의 annotation에 role-arnd을 추가해줘야하는데요
아래와 같이 values.yaml 파일의 serviceAccount → annotations 안에 추가해주면 됩니다.
values.yaml
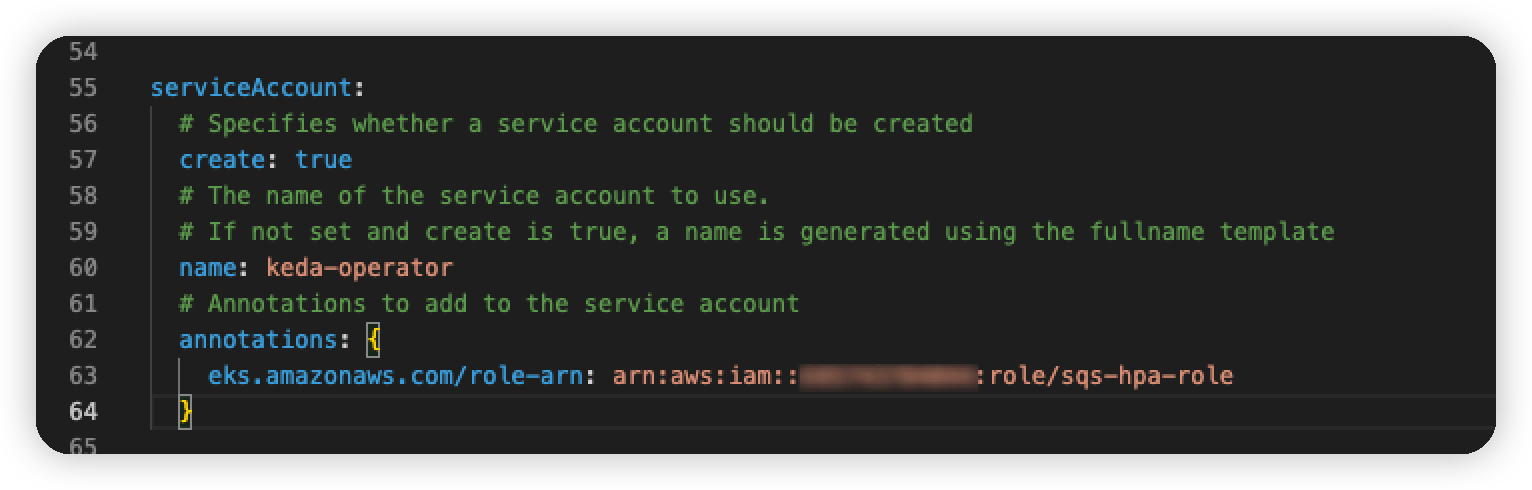
values.yaml 파일을 수정하면 helm 차트로 배포할 때 ServiceAccount의 생성하는데 해당 annotations에 추가되어 생성 적용됩니다.
그리고 ServiceAccount가 keda-operator에 적용되어 aws의 SQS 지표를 수집할 수 있게 됩니다.
Scaler작성하기
keda는 ScaledObject라는 커스텀 리소스를 이용해서 hpa를 자동 생성 및 제어하는 메커니즘으로 동작합니다.
aws sqs 지표를 얻기 위해 AWS CloudWatch 스케일러를 사용하였습니다
scaledObject yaml파일 예시
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: aws-sqs-worker-scaledobject
namespace: tagger-worker
spec:
scaleTargetRef:
name: target-example-deployment
minReplicaCount: 1
maxReplicaCount: 4
triggers:
- type: aws-cloudwatch
metadata:
namespace: AWS/SQS
dimensionName: QueueName
dimensionValue: "aws-sqs-queue-name"
metricName: ApproximateNumberOfMessagesVisible
targetMetricValue: "10000"
minMetricValue: "0"
awsRegion: "ap-northeast-2"
metricStat: "Average"
metricUnit: "Count"
metricStatPeriod: "60"
metricCollectionTime: "120"
identityOwner: operator
여기서 가장 중요한 몇가지 항목만 언급하겠습니다.
- minReplicaCount : 오토스케일의 최소 개수
- maxReplicaCount : 오토스케일의 최대 개수
- targetMetricValue : 메트릭의 타겟 값으로 여기에서는 sqs length 값
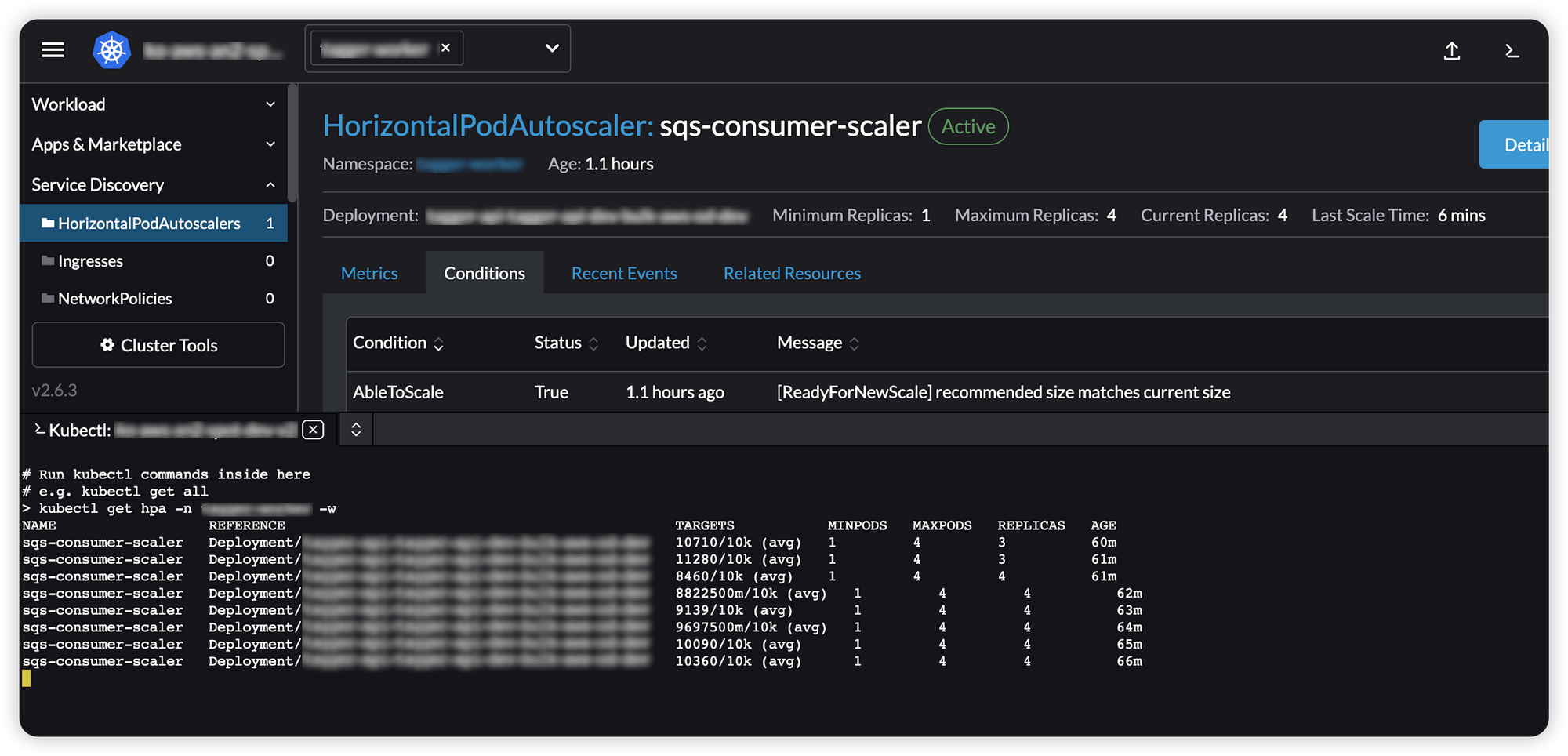
ScaledObject를 생성하면 aws-cloudwatch를 통해 지표를 수집하다고 10k건이 넘으면 자동으로 hpa 리소스를 생성하여 hpa 리소스가 pod 오토스케일링을 실시하도록 한다.
테스트 결과
targetAverageValue가 10k에 도달하거나 그 이상으로 상승했을 때 아래와 같이 hpa를 자동으로생성하고 스케일을 시작합니다.
HPA
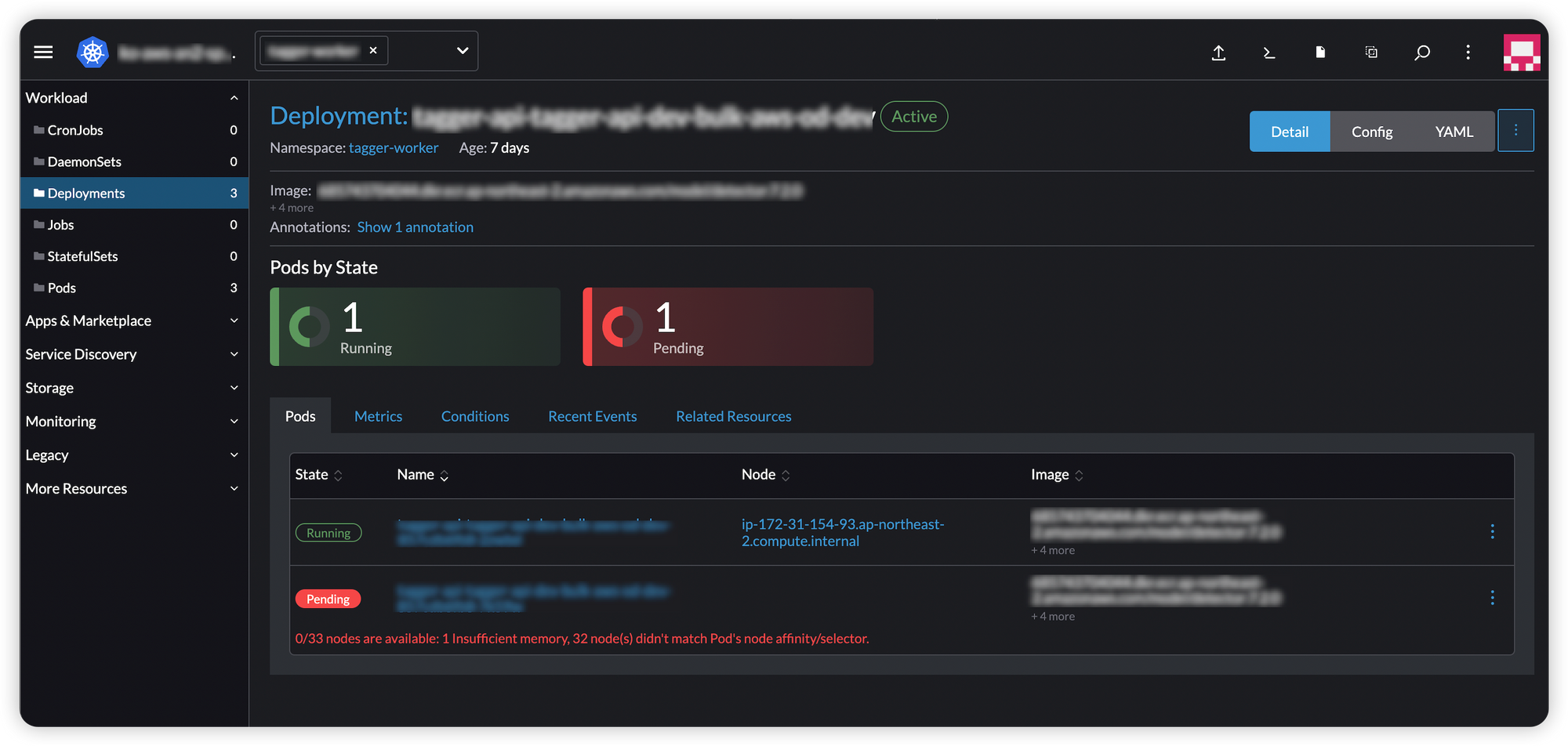
Deployment
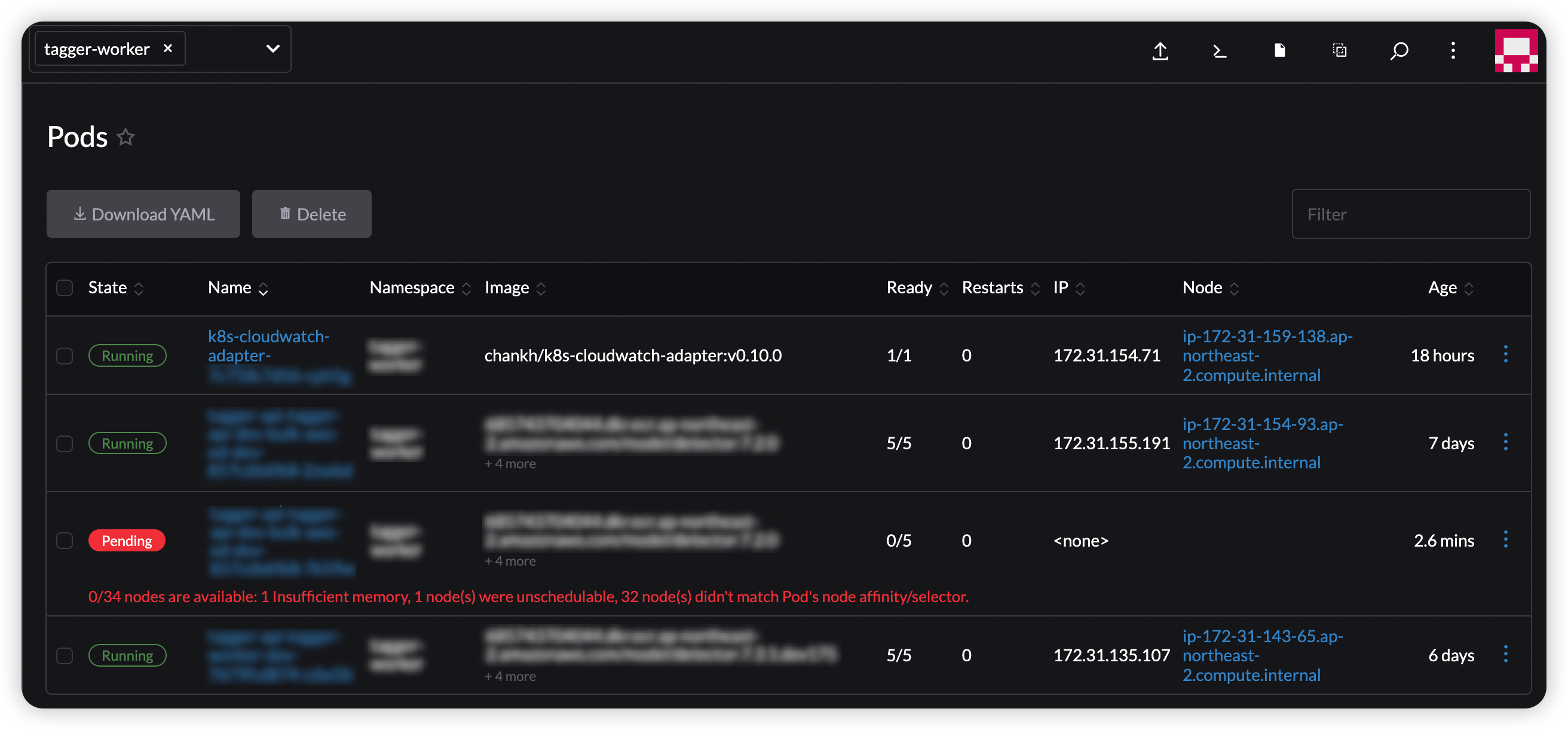
Pods
KEDA가 SQS Queue 지표를 이용하여 아주 만족스럽게 스케이업&다운이 되는 것을 확인하였습니다.
향후에는 SQS Queue를 이용하는 지표 뿐만 아니라 여러가지 지표를 활용하여 오토스케일링을 적용하여 서버자원을 효율적으로 사용할 수 있도록 할 계획입니다.
마치며
지금까지 KEDA를 활용하여 Pod의 오토스케일링을 CPU, Memory가 아닌 SQS Queue의 지표를 활용한 HPA 오토스케일링을 적용한 사례에 대해서 이야기했습니다. 특히 On-Premise 환경보다는 클라우드 환경에서는 리소스가 바로 비용이기 때문에 리소스 최적화를 위해서는 필수불가결의 요소라고 생각합니다.
쿠버네티스에서 기본으로 지원하는 지표로 HPA를 사용하기에는 다소 부족한 면이 많기 때문에 KEDA와 같은 서드파티 오픈소스를 활용하면 더 많은 지표를 활용하여 더 많은 리소스를 효율화, 최적화 가능하리라 생각합니다.
이 블로그를 보시는 분들도 KEDA를 많이 활용하여 좋은 결과를 얻으면 좋겠습니다
감사합니다.





