Since 2020, OMNIOUS has been operating all of its services based on Kubernetes, which has helped to significantly reduce the resources required for service operation with standardized interfaces and features such as autoscaling essential for stable service operation. This has allowed developers to focus more on service development and improvement rather than operational elements, but managing the constantly updating features of the cluster has been a burden.
Currently, We use multiple clouds, including on-premise, AWS, and GCP. AWS's EKS, for example, provides support only about a year after the official release of the Kubernetes version. Therefore, to receive stable support, the Kubernetes version of the cluster must be updated to the latest version within that period.
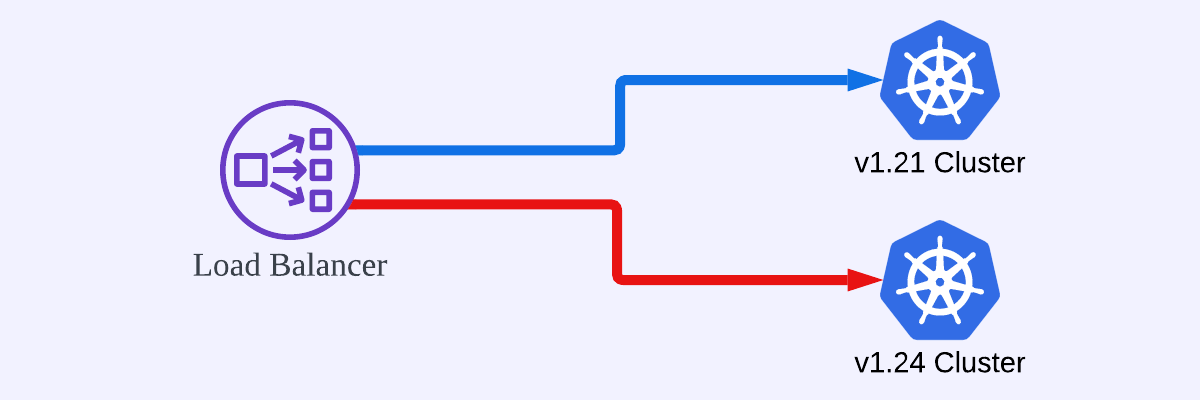
After updating to version 1.21 in early 2022, with the end-of-service date for version 1.21 approaching in February 2023, We recognized the need for an upgrade and began preparations in December 2022.
Strategies for Each Service Type
However, due to service expansion and increased customer usage, we needed to investigate its operational status more closely before proceeding with the upgrade. As a result, we identified four configurations that could be affected by the cluster upgrade. We classified them into those categories (refer to Figure 1).
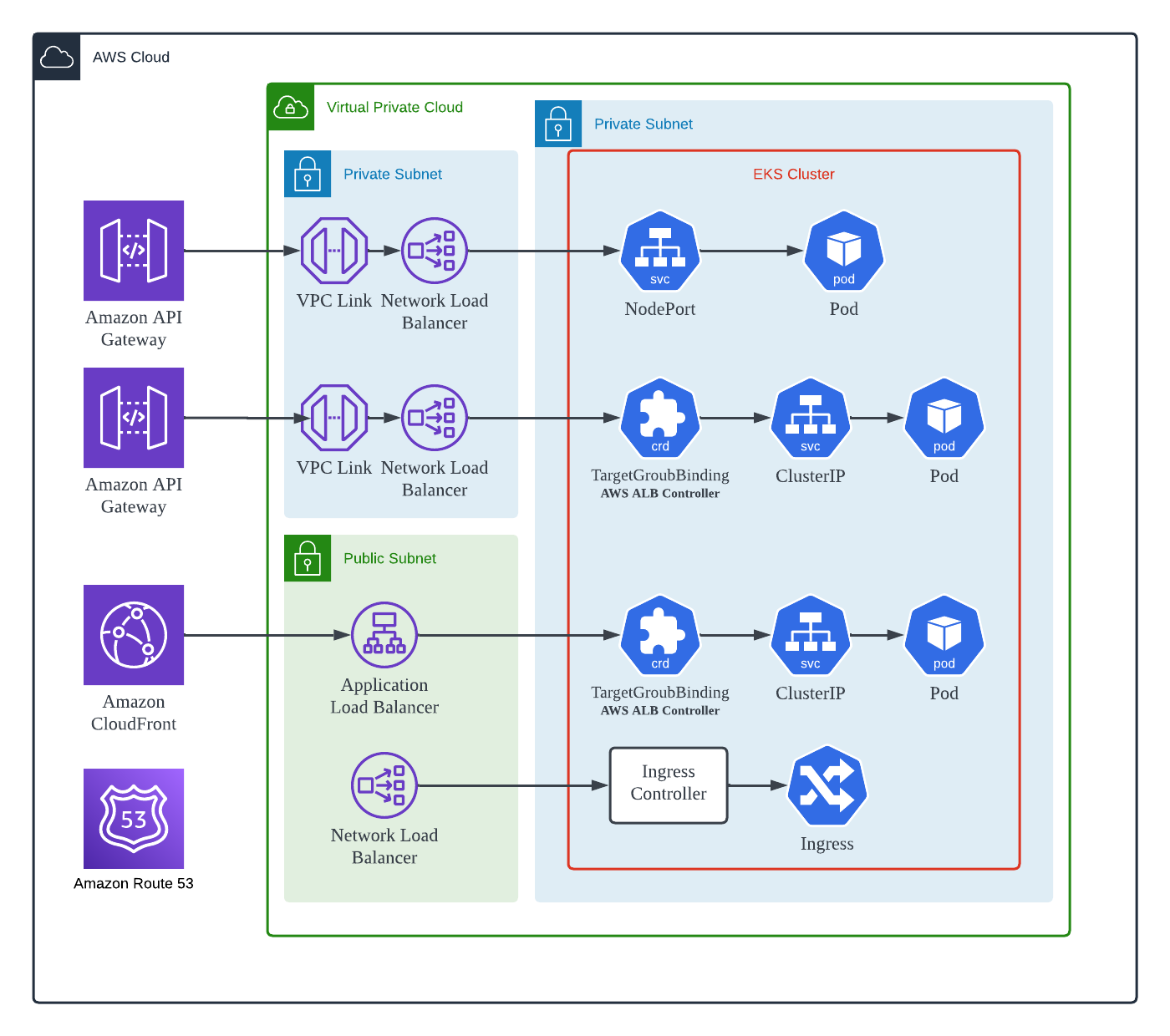
Upgrading the existing cluster could cause service interruptions, so we decided to create a new EKS cluster whose version is 1.24 and migrate our workloads one by one without downtime. Despite the increased operating cost during the migration period, this approach allowed for an immediate rollback if any problems occurred during the upgrade.
Thus, from December 2022 to January 2023, we developed and tested migration strategies for each of the four service types in a development environment similar to the production environment. As a result, we confirmed that the migration could proceed without downtime as follows.
Type 1. Workloads connected to the Load Balancer via NodePort
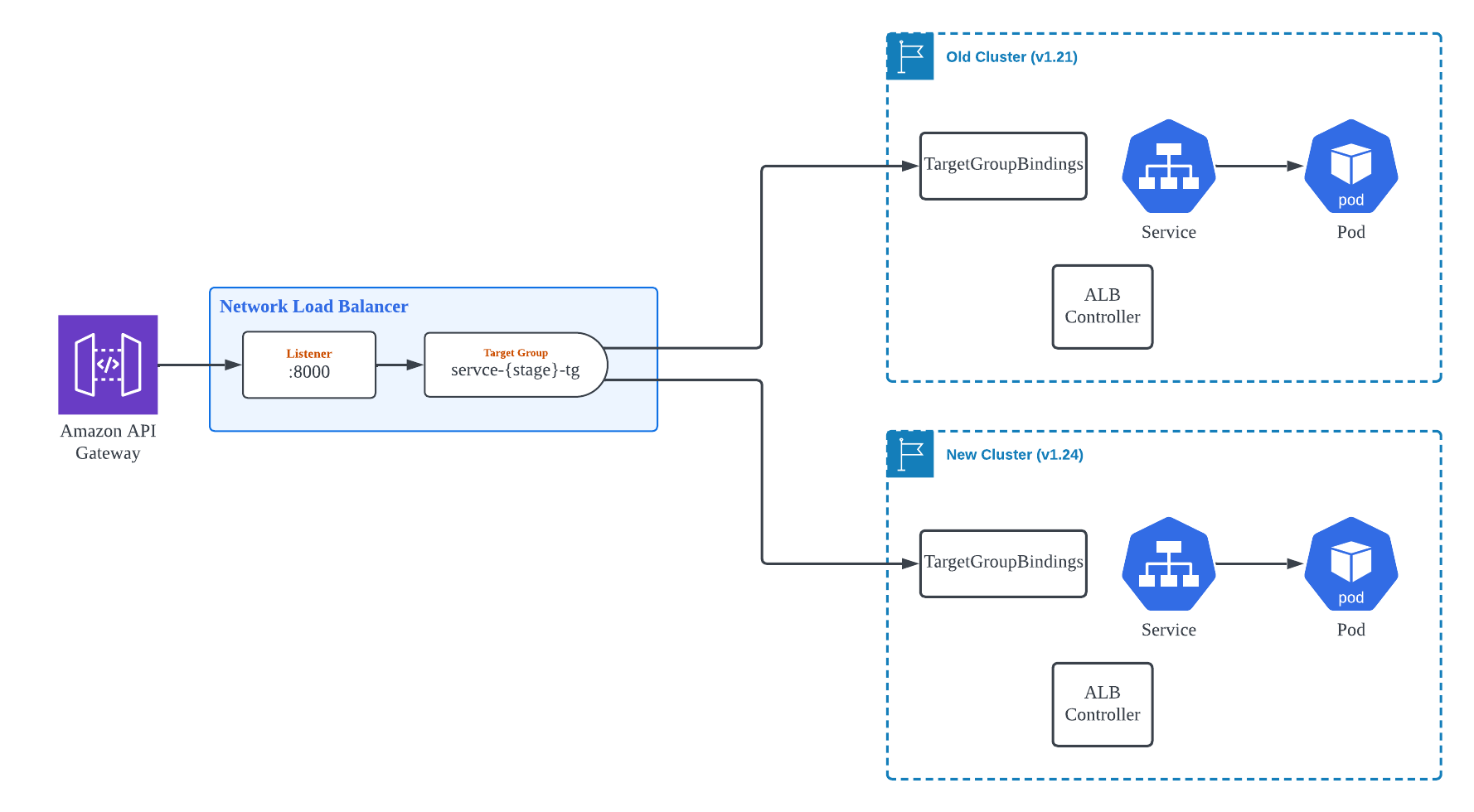
As illustrated as the first method in Figure 1, this method has been applied to the service for a long time, allowing external traffic to be controlled independently of the cluster. Thus, the Blue/Green deployment strategy was used to transition the traffic smoothly from the old to the new version of the cluster, as shown in Figure 2.
Type 2. Workloads connected to the Network Load Balancer via Pod IP Type using the ALB Controller
As applied since the middle of 2022, a custom resource called TargetGroupBinding defined in the AWS Load Balancer Controller, allows Workload Pods to be directly linked to Target Groups. This method, shown as (3) in Figure 3, is more efficient in AWS services as it uses the Pod IP directly assigned to the EC2 Instance of the Node in AWS EKS, without passing through an additional network layer. This configuration is very attractive from the perspective of service operation, and we thought there would be no problem applying and operating this method, but we faced issues during the Cluster Migration.
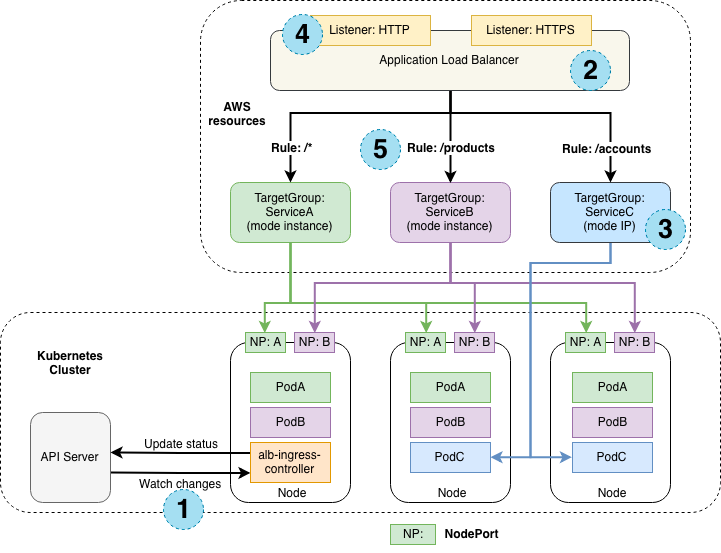
At first, we planned to proceed with migration by registering the Pod IPs of Workloads belonging to different Clusters in a single Target Group, as in Type 1 (refer to [Figure 2]). However, a problem occurred when ALB Controllers running in each cluster performed Pod IP registration on the Target Group. When the same Target Group is controlled from different Clusters, each Cluster's ALB Controller removes all other elements except for the valid Pod IP in each cluster, resulting in service disruption.
We searched for the ALB Controller's Github issue, an Open Source Project, to see if there is an official response to this problem. Currently, this method is not supported and is under consideration for the next version.
 kubernetes-sigs
kubernetes-sigsAfter considering how to proceed with zero-downtime migration, we eventually created independent Target Groups and devised a Blue/Green deployment strategy in the subsequent layer.
We set up two Target Groups, as shown in Figure 4, and each Target Group is connected to a separate EKS Cluster. Since only one Target Group can be connected per Listener for NLB, we created a new Listener with a unique Port number. After the two Target Groups and Listeners were healthy, we replaced the Port number of the Backend that the API Gateway's Resource-specific Integration settings refer to, enabling traffic to transit smoothly from the old cluster to the new cluster.
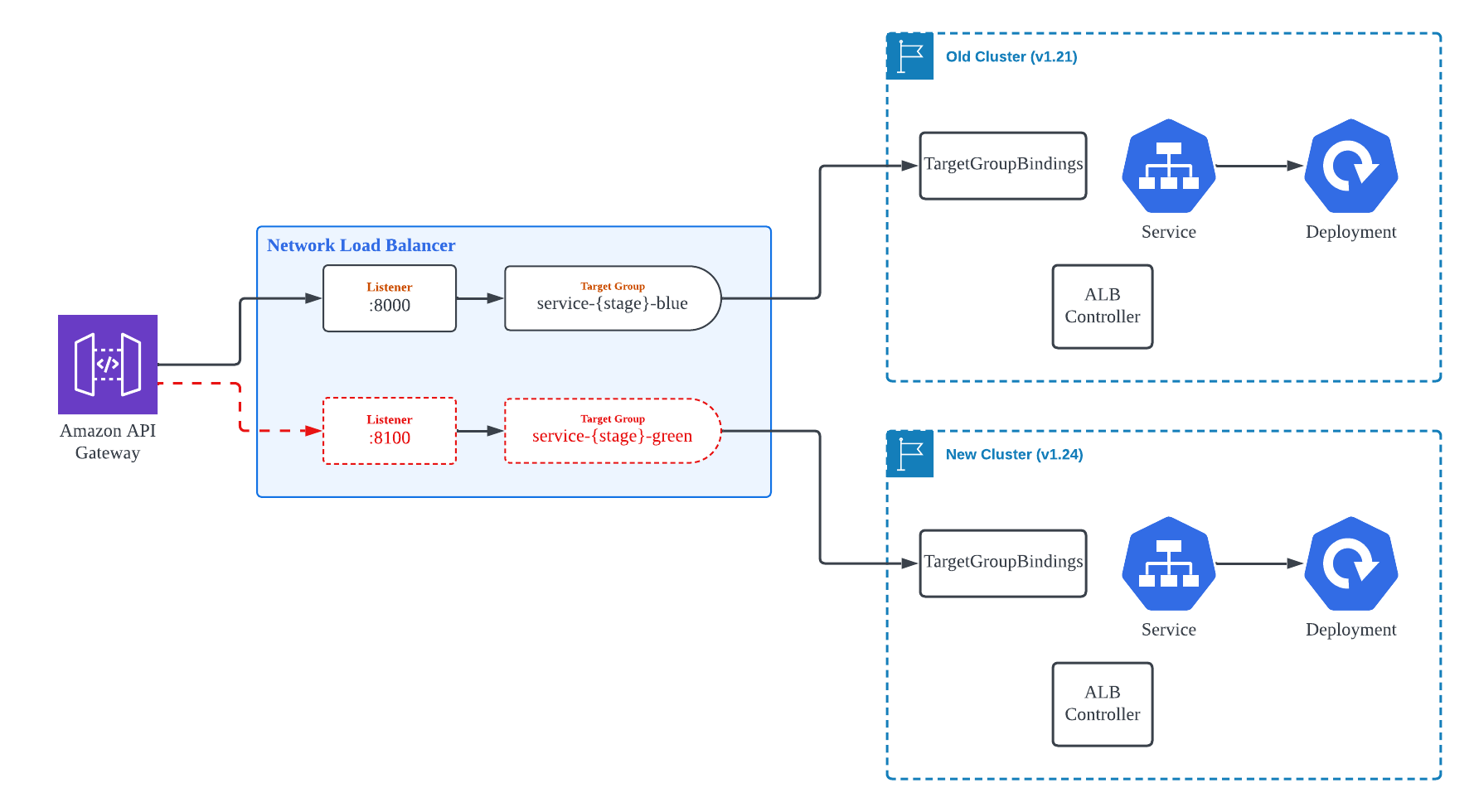
This method involves modifying many AWS resources, such as API Gateway, NLB Listener, NLB Target Group, and related Security Groups, so we simplified the control aspects that humans need to handle as much as possible by using control statements in Terraform such as for_each, count, and dynamic block, and modularized them so that they can be controlled through variables. As a result, in the actual operating environment, one developer was able to complete the migration of this type of workload within 1-2 hours without service interruption or failure.
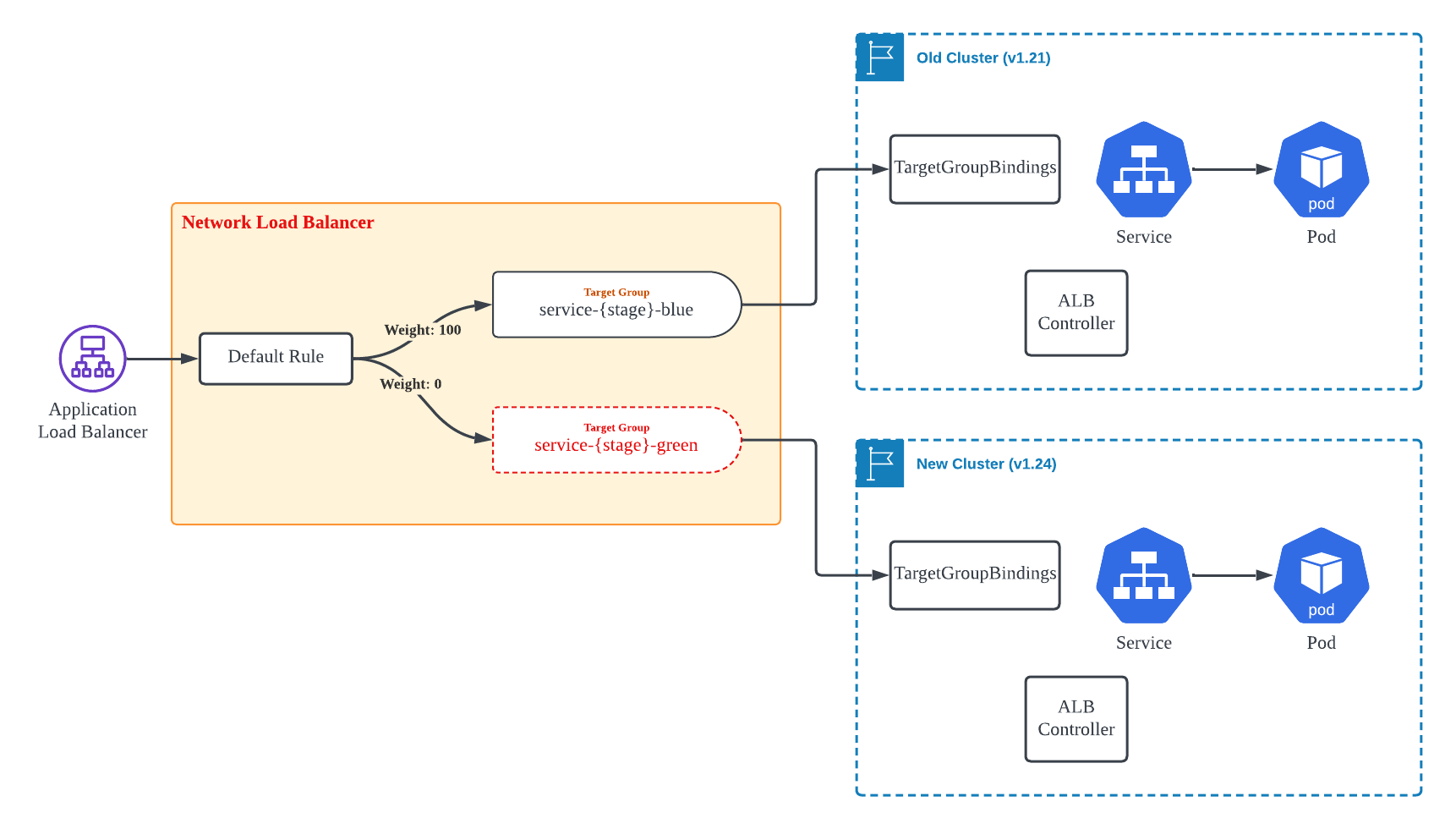
Type 3. Workloads connected to the Application Load Balancer via Pod IP Type using the ALB Controller
The work was easier for the Application Load Balancer than for the Network Load Balancer. While two Target Groups still needed to be created, the weight of each group could be adjusted through Routing Rule settings. While investigating migration options, we found this to be a helpful feature introduced in the latter half of 2019.
As shown in Figure 5, we initially registered the Target Group associated with the new cluster with a weight of 0. Once the workload on the new cluster was ready, we changed the weight to smoothly transition traffic to the new cluster. Doing so allowed us to carry out the migration without any service interruption.
Type 4. Workloads connected via Ingress Controller
The method shown in Figure 1 was used for services usually used only within the internal network. The migration process had no significant burden as no workloads required uninterrupted operation. If migration must be performed without interruption, it will be expected that traffic can be partially controlled by using DNS Records registered in Route53.
Conslusion
This big task required a lot of attention as it could have affected the running services. Therefore, it took almost two months, from December 2022 to January 2023, to develop a plan and conduct tests. All the developers who developed each service also participated in this task.
As a result, since we prepared thoroughly, it took only about a week to migrate the cluster of the production environment. During this period, practical developers spent only 1-2 hours daily completing each service's migration task. Although it is burdensome to think that we will have to do a similar job again next year around this time to match the Kubernetes version update, I think there will be no big problem in the future as there are team members who actively take responsibility for the services they are developing and cooperate.