Recently, the introduction of Generative AI-powered products such as ChatGPT, Github Copilot, and Amazon Codewhisperer has transformed the software development landscape. Traditionally, finding the right solution required developers to research and search for information by searching libraries, official documents, StackOverflow, or the GitHub issue pages. However, this often involved multiple failed attempts, as developers needed to have a good understanding of the situation, relevant keywords, and terms.
But with the use of Generative AI, developers can obtain the right information by simply having a few conversations, similar to asking a colleague. This can significantly increase their productivity and efficiency. The technology contains information on specific parameters that exist in major libraries, and can help to find less well-known details that may be difficult to find in official documents. It also provides examples of code that are customized for the developer's specific situation and the programming language they use. The result is a personalized tutorial document that is tailored to the individual's needs.
For example, I reached out to ChatGPT regarding an issue with the MySQL connection pool using the mysql-connector-python library in Python. Like below, I received a summarized answer about pool_reset_session parameter.
Q: In Python, I am using MySQL with connection pool with mysql-connector-python library. My Python process is running in long time. When connection are closed among the connection pool, the process failed to reconnect mysql. Is there any good way to prevent this errors?
A. Yes, you can prevent this error by using a connection pool that implements connection re-establishment or by implementing the logic yourself in your code. Additionally, you can set thepool_reset_sessionargument toTrueto reset the session for each new connection in the pool, or you can set theautocommitargument toTrueto automatically commit transactions after each query. Additionally, you can also implement a retry mechanism in your code to handle any connection errors and automatically retry the connection establishment process.
However, the answer I received was not practical as the default value of the pool_reset_session parameter in the MySQLConnectionPool class of the mysql-connector-python library is set to true. As a result, I asked for clarification with a follow-up question.
Q. These options are already used in MySQL-python-library because we use the connection pool function.
A. If these options are already used, you can try increasing thepool_sizeargument to ensure that there are enough connections in the pool to handle the load. You can also try increasing thepool_recycleargument, which specifies the number of seconds after which a connection should be automatically recycled. Another option would be to add a health check mechanism in your code that periodically verifies the status of the connections in the pool and replaces any closed or invalid connections with new ones.
In the second conversation, I received a more detailed answer about pool_size and pool_recycle arguments. I asked for an example code with a flask about it.
Q. Could you show an example in python flask?
A. Sure, here's a simple example of how you can implement a connection pool in a Python Flask application using the mysql-connector-pythonlibrary:from flask import Flask
import mysql.connector
app = Flask(__name__)
# Create a connection pool
cnx_pool = mysql.connector.pooling.MySQLConnectionPool(
host="hostname",
user="username",
password="password",
database="database",
pool_size=10,
pool_reset_session=True
)
@app.route("/")
def index():
# Get a connection from the pool
cnx = cnx_pool.get_connection()
cursor = cnx.cursor()
# Execute a query
query = "SELECT * FROM table"
cursor.execute(query)
result = cursor.fetchall()
# Release the connection back to the pool
cnx.close()
return str(result)
if __name__ == "__main__":
app.run()
In this example, a connection pool is created when the application starts, and a connection is obtained from the pool whenever a request is made to the indexendpoint. After the query is executed, the connection is closed and released back to the pool, ready for use in future requests. This way, you can reuse existing connections instead of creating a new connection for every request, improving performance and reducing the risk of connection errors.The generated example code was missing information regarding the pool_size and pool_recycle arguments mentioned in previous answers. It seemed that the context of the conversation wasn't always carried over. So, I requested an example code that included a solution to reconnect if errors occurred while thinking while having a conversation.
Q. As you know flask app can run in long time until new client connection estabilshed. during this period if connection is closed, how to set reconnect before new client connection come in?
A. You can implement a reconnect mechanism in your Flask application to handle closed connections. You can wrap the database query in a try-except block and catch any connection errors. If a connection error occurs, you can attempt to reconnect to the database and retry the query. Here's an example:
import mysql.connector
from mysql.connector import Error
# Create a connection pool
cnx_pool = mysql.connector.pooling.MySQLConnectionPool(
host="hostname",
user="username",
password="password",
database="database",
pool_size=10,
pool_reset_session=True
)
def get_data_from_db():
# Get a connection from the pool
cnx = cnx_pool.get_connection()
cursor = cnx.cursor()
try:
# Execute a query
query = "SELECT * FROM table"
cursor.execute(query)
result = cursor.fetchall()
except Error as e:
# Handle connection errors
print("Error: {}".format(e))
# Reconnect to the database
cnx_pool.reconnect()
cnx = cnx_pool.get_connection()
cursor = cnx.cursor()
# Retry the query
cursor.execute(query)
result = cursor.fetchall()
# Release the connection back to the pool
cnx.close()
return result
@app.route("/")
def index():
result = get_data_from_db()
return str(result)
In this example, if a connection error occurs, the code will attempt to reconnect to the database and retry the query. If the reconnection is successful, the query will be executed again, and the result will be returned. If the reconnection fails, you can add additional error handling logic to handle the failure.
With just a few conversational exchanges, I received a solution nearly fit for my issue. Upon request, it even provided a relevant code example to support the solution. However, MySQLConnectionPool class has not to reconnect() method. While there were instances where the solutions were too general, or context was not sustained, I was able to raise follow-up questions to clarify and close to my issue.
An AI assistant can significantly enhance the efficiency of the coding process. I recently tested GitHub Copilot, which has an integrated IDE plugin. The plugin provides code suggestions based on class names, functions, and arguments, enabling developers to execute their plans easily and quickly.
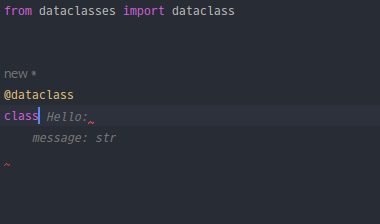
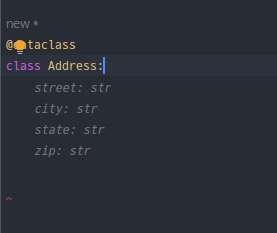
The capabilities of GitHub Copilot's AI assistant were demonstrated when I used the @dataclass decorator and typed "class." The assistant generated a general definition for dataclasses, as illustrated in the first screenshot. When I entered the class name "Address," the assistant recommended typical components for an address book, demonstrating its usefulness, as seen in the second screenshot.
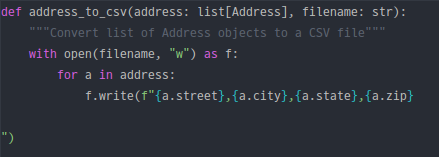
Regarding functions, with function names and arguments, it seems to generate a general code block like the screenshot below. Although there were some minor noises, such as unnecessary line breaks in the write function, it was still helpful as it provided working example codes.
If you're using a library for the first time or need to write a new business logic, you can get help right away on the IDE screen without having to search for examples in a separate browser window by just using the code presented on the screen.
In this post, I tried both ChatGPT and GitHub Copilot. Both were found to reduce the effort for developers to solve problems or search for information, but contain some noise and errors. This is similar to when a driver operates a semi-autonomous car, there is still a risk of an accident if the driver relies solely on the car. Ultimately, the developer must make the final choice based on their own experience and knowledge, considering the context.